{kind=link}
Project page template is borrowed from DreamFusion.
Abstract
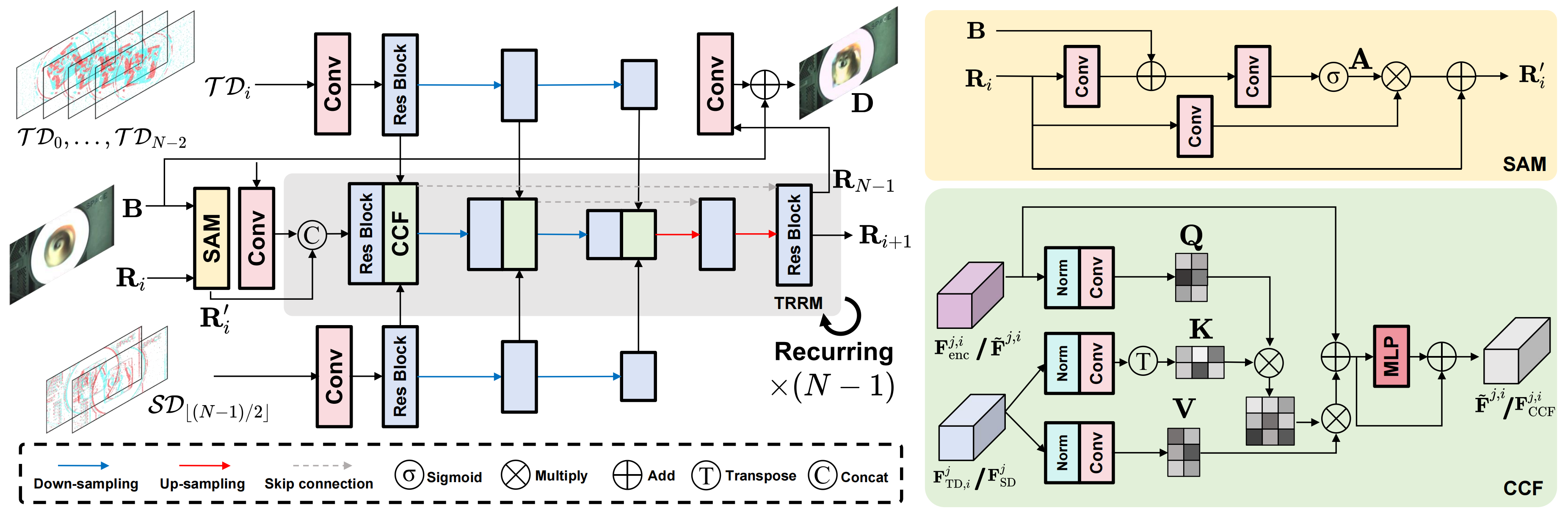
Based on the complementary vision sensor (CVS), Tianmouc, we propose $\textbf{S}$patio-$\textbf{T}$emporal Difference $\textbf{G}$uided $\textbf{D}$eblur $\textbf{N}$et (STGDNet) for motion deblurring. It achieves strong performance in real-world extreme blur scenarios.